Introduction
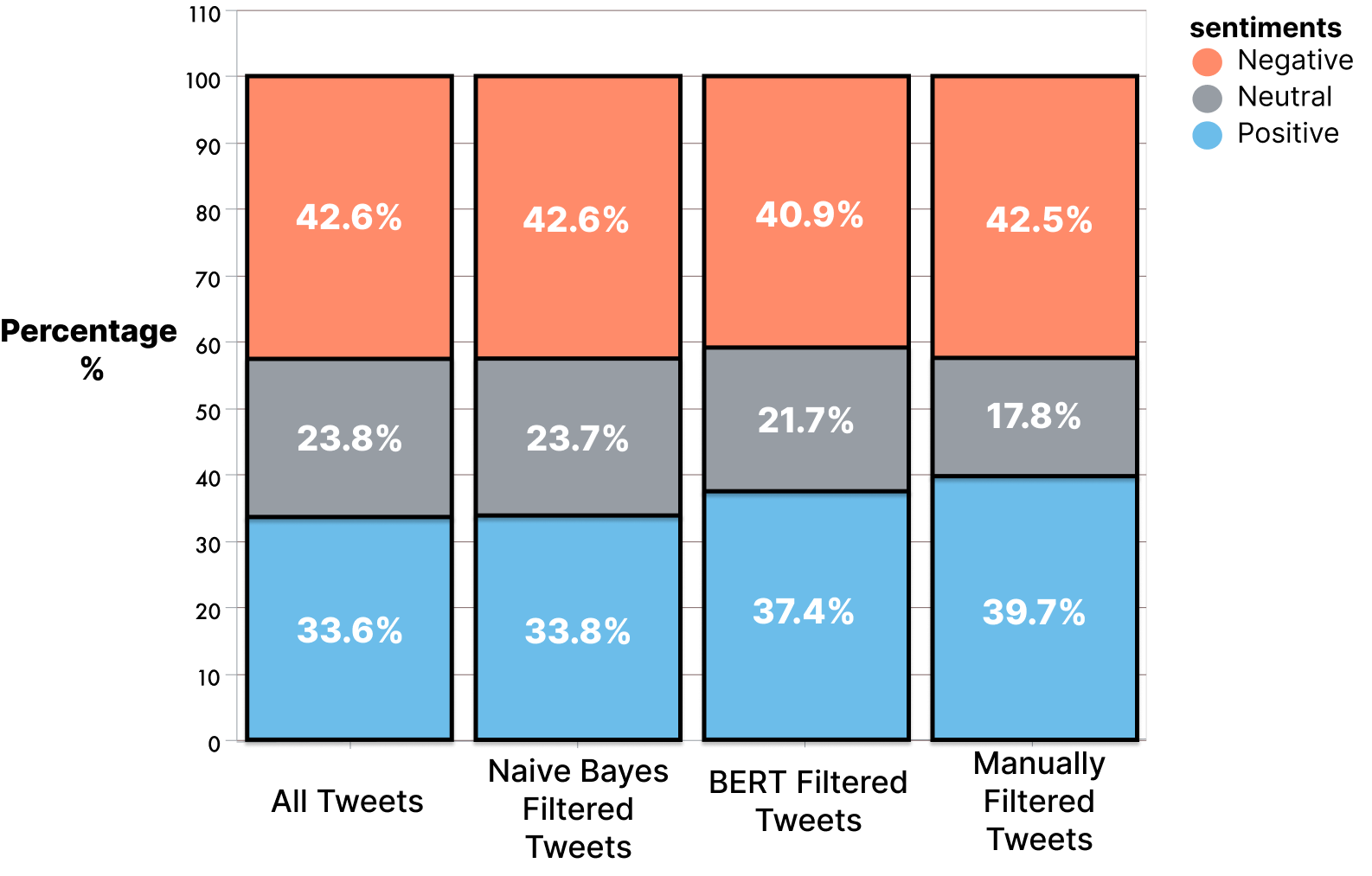
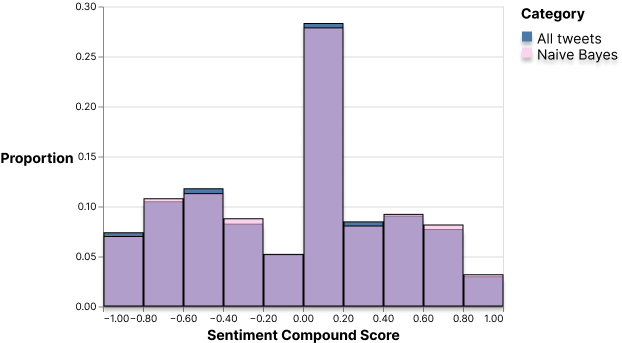
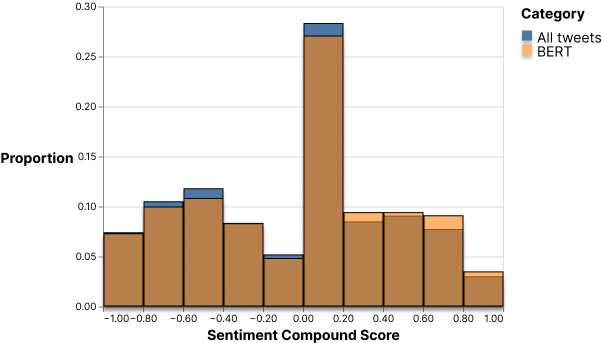
With the exponential growth of microblogging social media platforms such as Twitter and Facebook in the last two decades, the issue of spam has followed the same trajectory. Spam is unsolicited and unwanted messages used to deceive and negatively impact the experience of other users. Since spam in social media is prevalent in our society today, we believe that it is necessary to investigate how public sentiment will change after accounting for spam because people are using social media as a way to gain information and form their opinions. It is important to see if a larger effort should be made in the fight against spam because it is dangerous if spam is misinforming and skewing large amounts of opinions. We believe that this issue is extremely prevalent in the topic of abortions because it is a controversial topic and contains lots of spam with the recent growth in public attention that it has received with the politicization of it. To perform this experiment, we will be using two different models for spam detection: a simpler Naive Bayes classifier and a more advanced transfer learning model based on Google’s BERT which will be complemented by NLTK VADER for sentiment analysis.
Streaming Pipeline
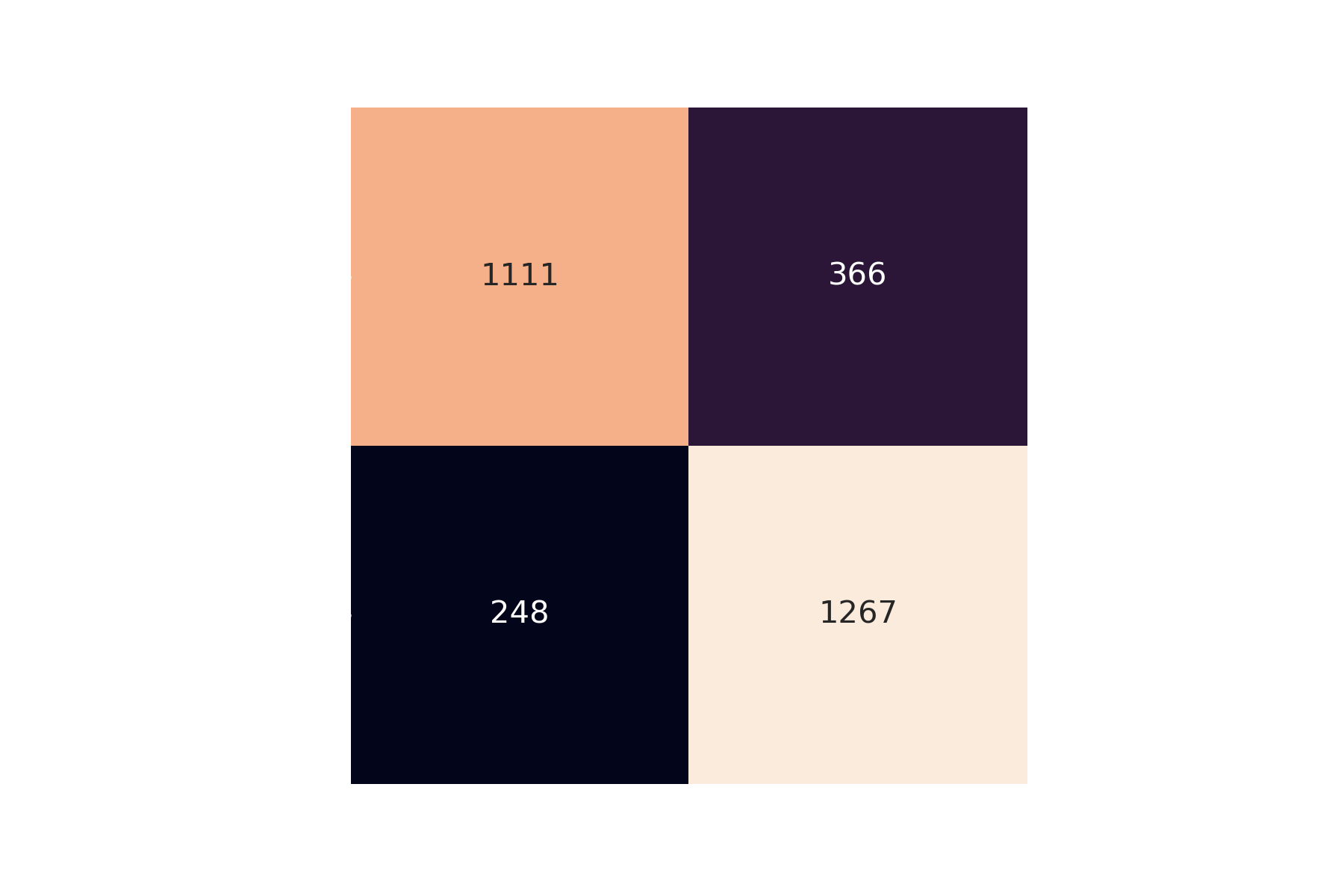
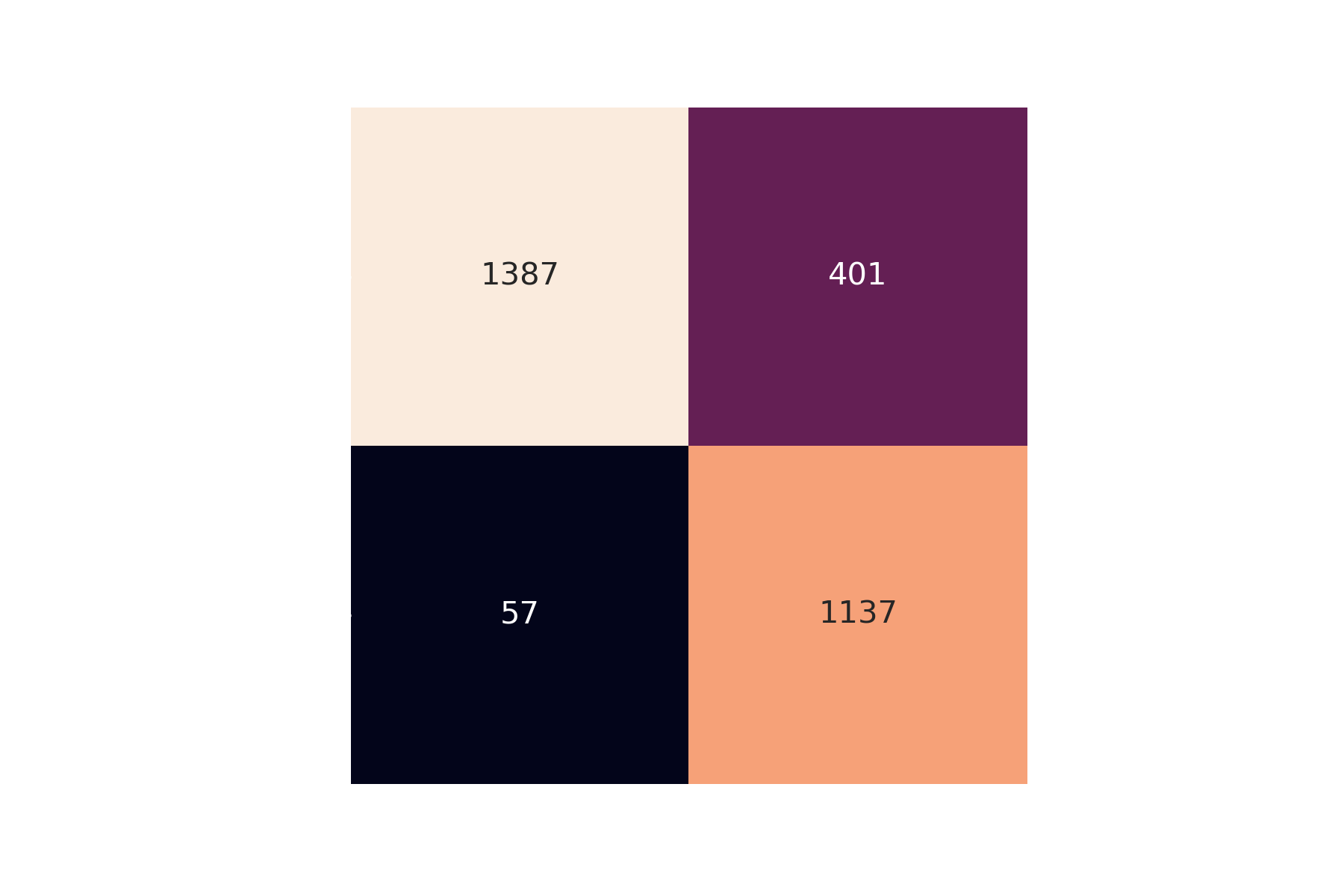
We created a durable messaging system using Pulsar and Astra streaming to obtain real time tweets on abortion from Twitter to simulate the same experience that a user would get if they were on Twitter looking up abortion. In general, social media users are looking for the latest about what is going on, that is why it is necessary to use a method like a streaming pipeline to get the same feed a user would get. The benefit of using a real time messaging system is that the insights that we gain are not outdated like we would have gotten if we went with a batch processing model. The framework for the pipeline has four main components: data retrieval, spam detection, sentiment analysis, and visualization. We use Pulsar’s publish-subscribe pattern to effectively process the raw results from the Twitter API. As we can see in the figure below, the streaming pipeline provides a seamless experience of retrieving and transforming the tweets to be stored in the database.